Revolutionise Structural Engineering with ChatGPT and SOFiSTiK
Written by Diego Apellániz, Head of Design and Prokurist at EDD Holding – Engineering Digital Design.
The AI revolution is undeniably upon us, spearheaded by accessible large language models (LLMs) such as ChatGPT. As these models gain popularity, professionals from all industries are exploring ways to leverage them. For us structural engineers, the goal is to integrate AI into our daily workflows. And what would be a better discipline than structural analysis due to the significant amount of time we invest in this task?
ChatGPT’s ability to process and generate code comes into play in this context. It can be applied with structural analysis software that provides APIs to automate some of their functionalities. However, the uniqueness of SOFiSTiK lies in its 100% code-based model construction, using its proprietary language, CADiNP. Furthermore, unlike other AEC industry languages such as IFC, CADiNP provides resources such as groups, loops, and automatic mesh generation for efficient, repetition-free coding. This approach aligns perfectly with how ChatGPT generates code, opening up exciting prospects for automating structural analysis with SOFiSTiK.
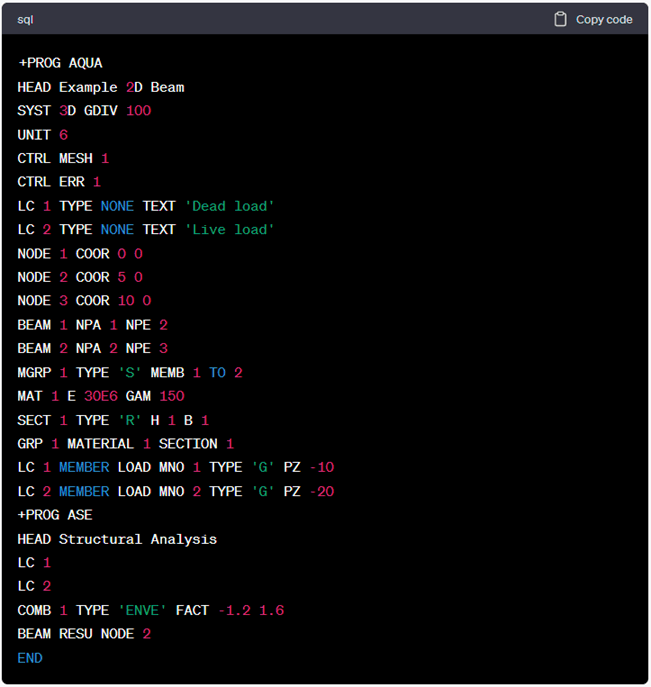
However, this task is not as straightforward as it seems. When directly asking GPT-4 (the most advanced model of ChatGPT publicly available at https://chat.openai.com/) to generate a simple teddy file of a SOFiSTiK model, it actually generates a code chunk that resembles CADiNP (see Figure 1), however, after a closer inspection, it can be noticed that there are plenty of bugs in this code, since some the module AQUA is not properly closed, the definition of load cases don’t belong in this module, some of the keywords don’t even exist, etc.
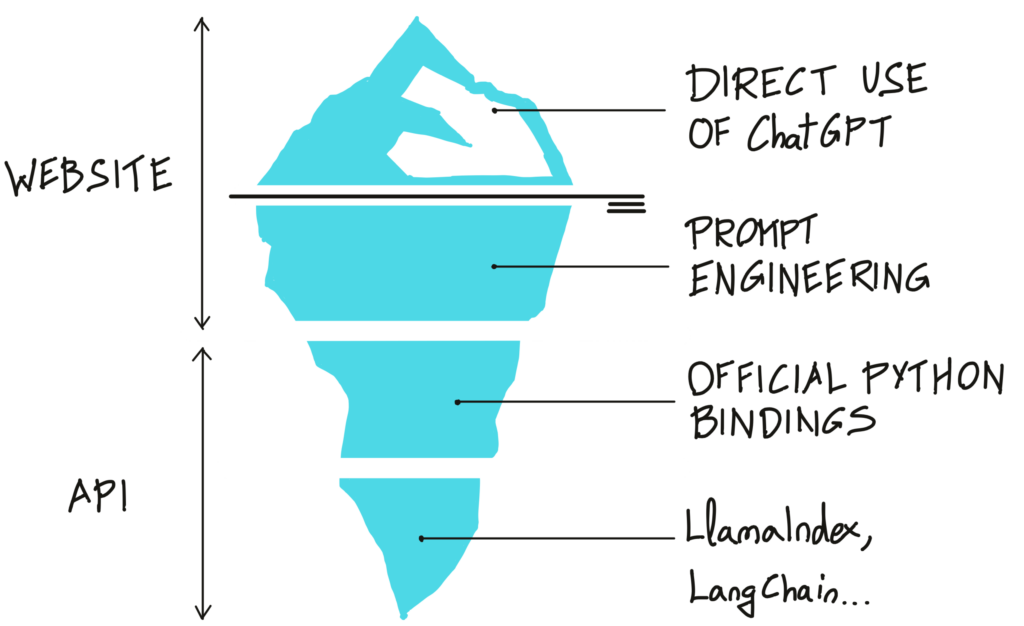
Despite this first unsuccessful attempt to connect ChatGPT with SOFiSTiK, it must be pointed out that there are other strategies to get the most out of ChatGPT. Figure 2 shows the different layers of an iceberg representing the potential of ChatGPT. Deeper layers present a more powerful approach, but the complexity of these approaches progressively increases as well!
- Direct use of ChatGPT: The user messages or prompts fed into ChatGPT are merely questions posed without providing additional context or further information. Most users just scratch the surface of the potential of ChatGPT.
- Prompt engineering: Techniques to optimize the prompts provided to ChatGPT so the messages returned by ChatGPT fulfil the user intent better.
- The official Python bindings: The official Python module allows the user to interact with ChatGPT not through its public web interface but through its API, which offers more resources and opens up more possibilities than the web interface.
- Unofficial libraries such as LlamaIndex and LangChain: There are more and more third-party libraries built on top of the official bindings of ChatGPT. Two of the most popular of them are LlamaIndex and LangChain. LlamaIndex connects ChatGPT with custom documents so that the users can ask ChatGPT questions about their own data. LangChain is a framework to develop AI agents based on LLMs that can carry out a set of different tasks based on users’ requests, such as surfing the web, interacting with other APIs, querying custom data, etc.
Consequently, prompt engineering is the next strategy to try to automate structural analysis with ChatGPT and SOFiSTiK. This approach can turn out to be very successful, as shown in the youtube tutorial SOFiSTiK and GPT-4 Tutorial: How to talk to your structural model.
These are some recommendations to get efficient and error-free CADiNP code from ChatGPT:
- Each conversation with ChatGPT should focus on a certain topic. Do not mix up in a chat restaurant recommendations with SOFiSTiK prompts. With each message sent to ChatGPT, the user is actually sending the whole conversation of previous messages up until that point. Therefore, mixing topics can confuse ChatGPT.
- Furthermore, each conversation should start with a general instruction to ChatGPT explaining the user intention, the structure of the following messages and the role ChatGPT should assume in the conversation. For this purpose, we want ChatGPT to become an assistant that transforms our prompts into CADiNP code. It is also advisable to ask ChatGPT to respond with concise and compact messages.
- However, the key prompt engineering technique is to provide ChatGPT with sufficient examples and documentation about the SOFiSTiK syntax so it learns how the CADiNP language works. Each prompt that focuses on a new module or a new record that ChatGPT has not seen yet should include that information besides the user request.
- It is also worth breaking down complex instructions into several simpler prompts.
- Once the SOFiSTiK file gets longer and longer, it is advisable to ask ChatGPT in new messages to write unmodified sections of the code as generic comments. Otherwise, ChatGPT may hit its limit of characters per response, and the returned SOFiSTiK code may be incomplete.
- If ChatGPT finds difficulties translating a certain complex instruction into SOFiSTiK code, a possible solution may be to ask ChatGPT to explain its reasoning to try to satisfy our request as a comment beside each record or line. LLMs are trained to generate text fragments that make sense. With this technique, we force ChatGPT to generate a response that is on its own coherent with our instruction and thus maximize the chances of getting satisfactory responses from ChatGPT.
- Do not aim for 100% right answers from ChatGPT. We must strive for efficiency and not for perfection. It is fine if the user has to correct a small bug or inaccuracy in some responses since checking the output from ChatGPT is always required. Nevertheless, it is important to let ChatGPT know about our manual input to the SOFiSTiK file so that it can integrate these changes in future responses.
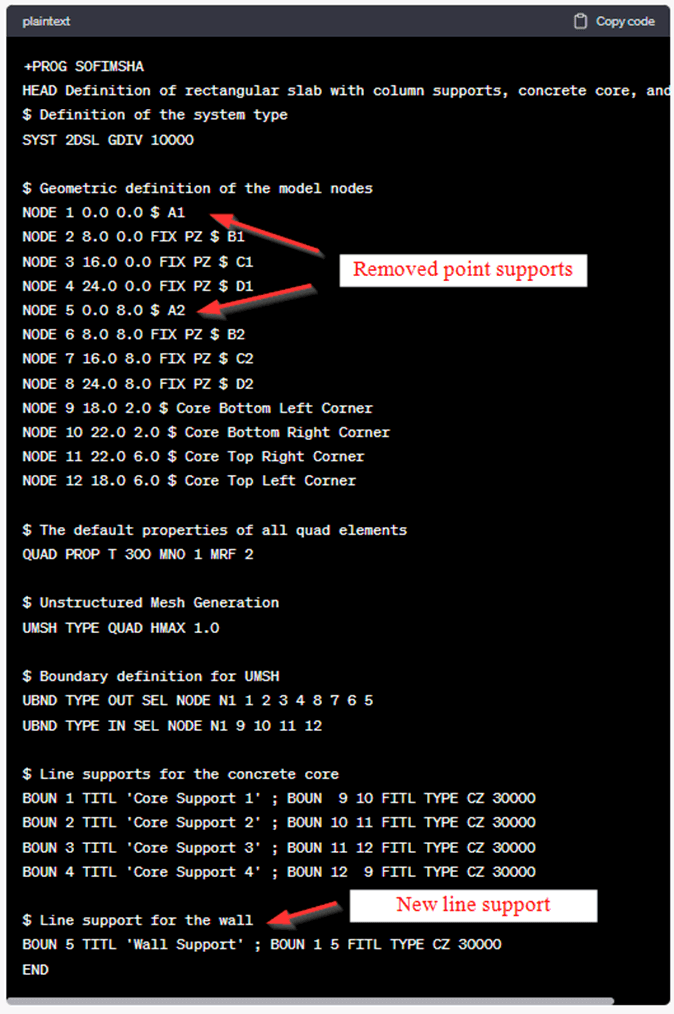
Figure 3 shows a successful response from ChatGPT to the user prompt: “We want to update the model again. Remove the columns on the nodes A1 and A2 and add a wall represented by a line support connecting those nodes.” Needless to say, this interaction took place after several previous messages in which ChatGPT had been provided with abundant information about the syntax of the SOFiSTiK language CADiNP. There can be noticed two significant accomplishments from this response. The first is that ChatGPT can successfully generate complex CADiNP code from simple user instructions. The second and arguably more significant accomplishment is that ChatGPT can translate plain language into the SOFiSTiK code. The user merely refers to “structural elements” such as columns and to the “Grid nodes A1 and A2” instead of referencing specific code lines or keywords. Users can, therefore, directly talk to the SOFiSTiK model in plain language terms!
To achieve such an interaction with ChatGPT, the user must first explain to ChatGPT the relationship between the actual building elements and the SOFiSTiK code and ask ChatGPT to write down this information as a comment right to the corresponding records (as it can be noticed in Figure 3 too) so this information is easier to remember for ChatGPT. An exemplary prompt for this would be: “Write the node axis in a comment next to the node definition. The X coordinate refers to the grid axis A, B, C, D, and the Y coordinate to the grid axis 1 and 2.”
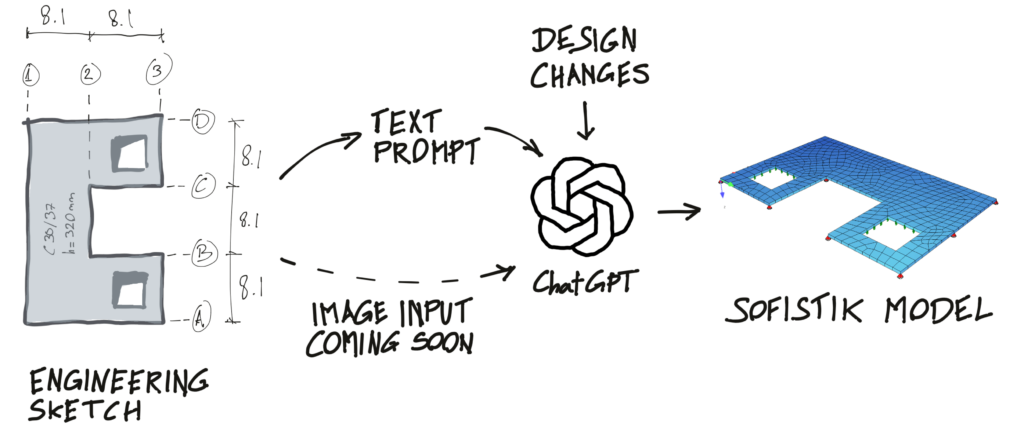
This workflow is summarized in Figure 4. The process starts with an engineering sketch since this is typically how engineers summarize and check their ideas before building any calculation model. The next step would be translating this sketch or idea into text prompts that ChatGPT can understand following the above-described prompt engineering techniques. Soon, it will be possible to input a sketch into ChatGPT directly, but OpenAI has not enabled this possibility for external users yet. Once we have provided ChatGPT with enough information about our building or model, it can generate the Teddy file of the SOFiSTiK model and easily modify it in case of design changes that may be communicated in plain text to ChatGPT.
To put this workflow into context, we benefit from ChatGPT’s artificial neural network (ANN) to generalize the SOFiSTiK documentation and examples we provide to our particular modelling requirements. The capacity of an ANN to apply generalizations to new data based on a limited amount of training data is directly related to the number of parameters of the ANN. To quote some examples from my Grasshopper AI plug-in “Pug,” (https://www.food4rhino.com/en/app/pug) that allows the user to define and train custom ANNs using the Tensorflow library, an ANN that can identify hand-written numbers has 55000 parameters. An ANN that can play the Snake game on a super-human level has 30000 parameters. In this article, we are dealing with GPT-3.5, which has 175 billion parameters and with the more advanced GPT-4 whose number of parameters has not been disclosed yet. We are then talking about models that are around “seven”! orders of magnitude bigger than custom ANNs. Such large neural networks require very expensive hardware to be trained, and the fact that these extremely powerful trained LLMs are publicly accessible leads to a paradigm shift in many industries.
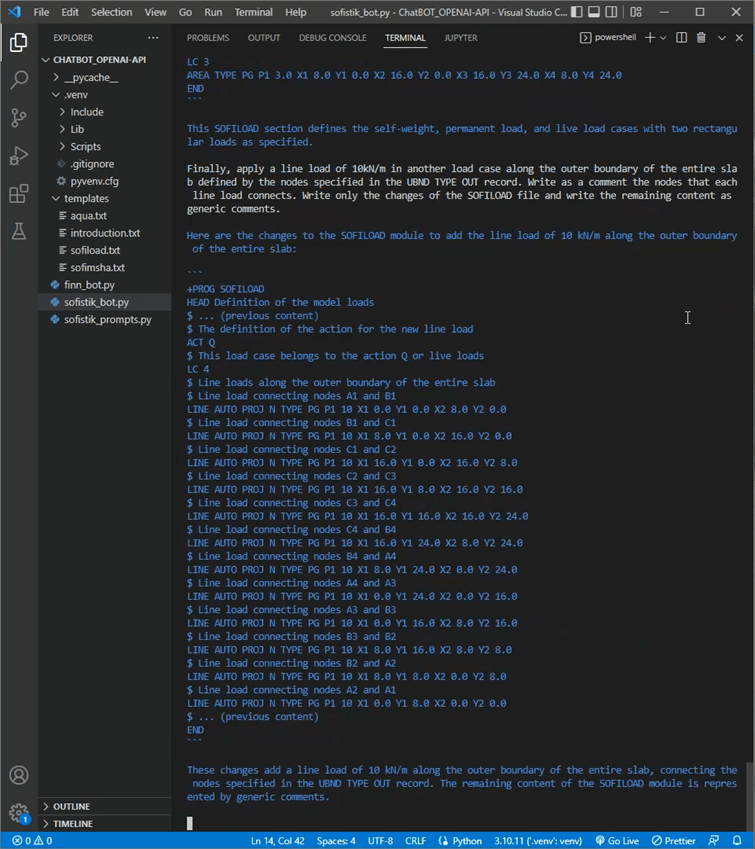
The main disadvantage of this workflow is the need for users to set up their own examples or templates so ChatGPT can learn from them to generate error-free CADiNP code. Nevertheless, this process may be automated to a certain extent using OpenAI’s API. The following Youtube tutorial explains a suggested approach to programming an AI Bot using the official Python. Introduction to the OpenAI API – Programming a Chatbot to generate SOFiSTiK models. This coding project results in a dialogue interface in which users need to specify a certain keyword to load the corresponding SOFiSTiK template sent to ChatGPT in the background. This fluent dialogue is shown in Figure 5.
It can be noticed that the API offers more possibilities than the official website of ChatGPT. Such AI bots can also be integrated into custom web interfaces so they are easily accessible by remote users. Furthermore, another attractive advantage of the API is that messages sent to ChatGPT through this approach are confidentially treated and deleted after 30 days: https://openai.com/policies/api-data-usage-policies.
To conclude, it is clear that there is still a world of unexplored potential at the intersection between ChatGPT and SOFiSTiK. The discussed strategies only scratch the surface of what is possible when these powerful tools are combined. Prompt engineering, API use, and integration with unofficial libraries have shown promise, but the rapidly evolving landscape of large language models (LLMs) means there is always more to discover.